
Działanie w praktyce
W poprzednim artykule skupiliśmy się na podstawach pracy z wyrażeniami regularnymi. Poznaliśmy kilka najprostszych elementów oraz pracowaliśmy z przykładami.
Jeśli ktoś z Was nie widział pierwszej części to może ją znaleźć tutaj.
W drugiej części artykułu o wyrażeniach regularnych chciałbym pokazać Wam jak użyć ich w praktyce.
Do tego celu posłużę się najpopularniejszym darmowym IDE jakim jest Visual Studio Code.
Każdy edytor tekstu posiada wbudowane narzędzie do wyszukiwania znaków za pomocą regexów. W VSC wyszukiwarkę tekstu możemy uruchomić za pomocą skrótu klawiszowego ctrl+f a narzędzie do podmiany tekstu ctrl+h.
Narzędzie to ma 2 tryby wpisywania. Możemy użyć zwykłego ciągu znaków (tak jak w każdej wyszukiwarce), lub posłużyć się wyrażeniami regularnymi.
Możemy także określić czy zwracamy uwagę na rozmiar liter oraz całe wyrazy.
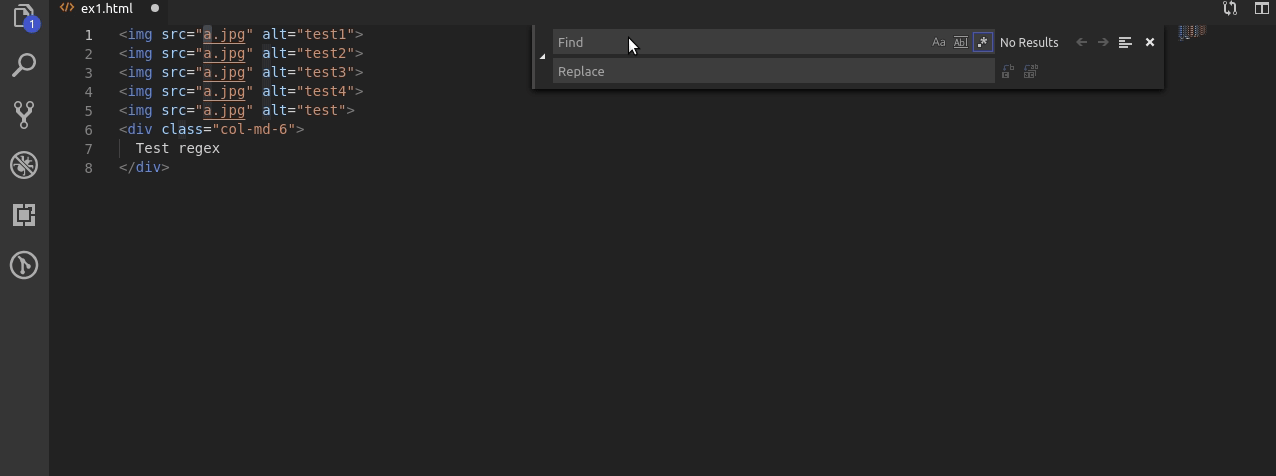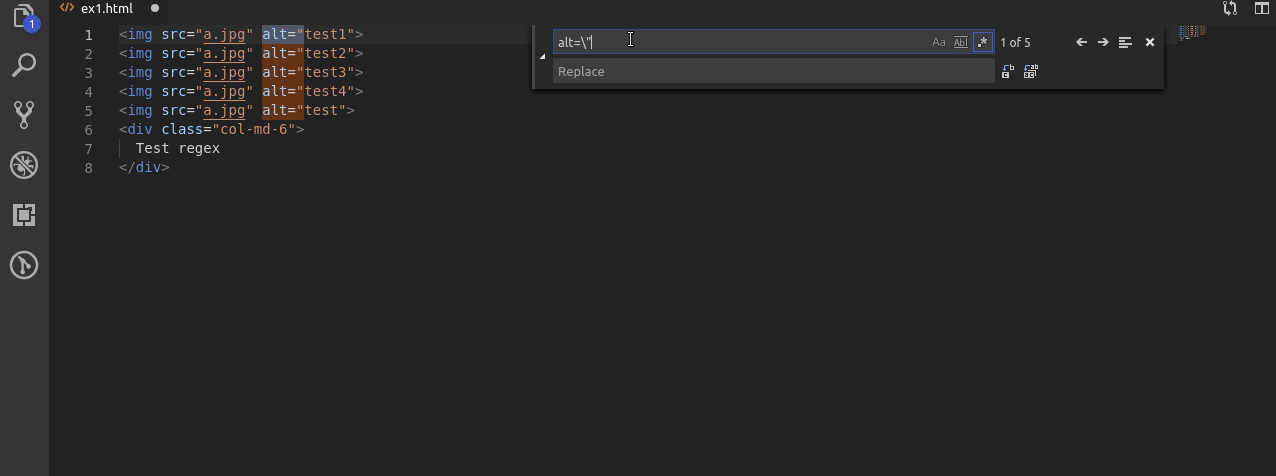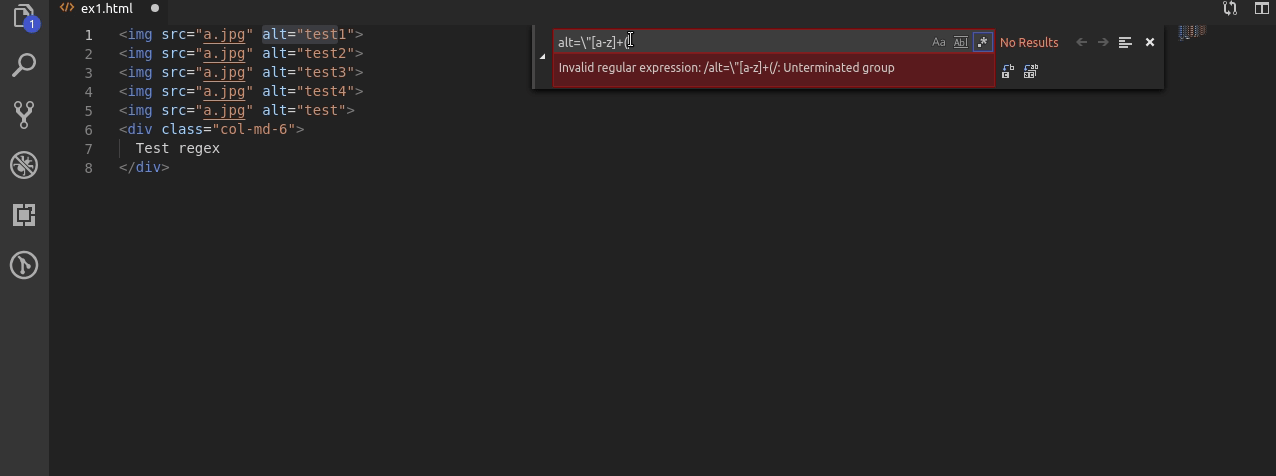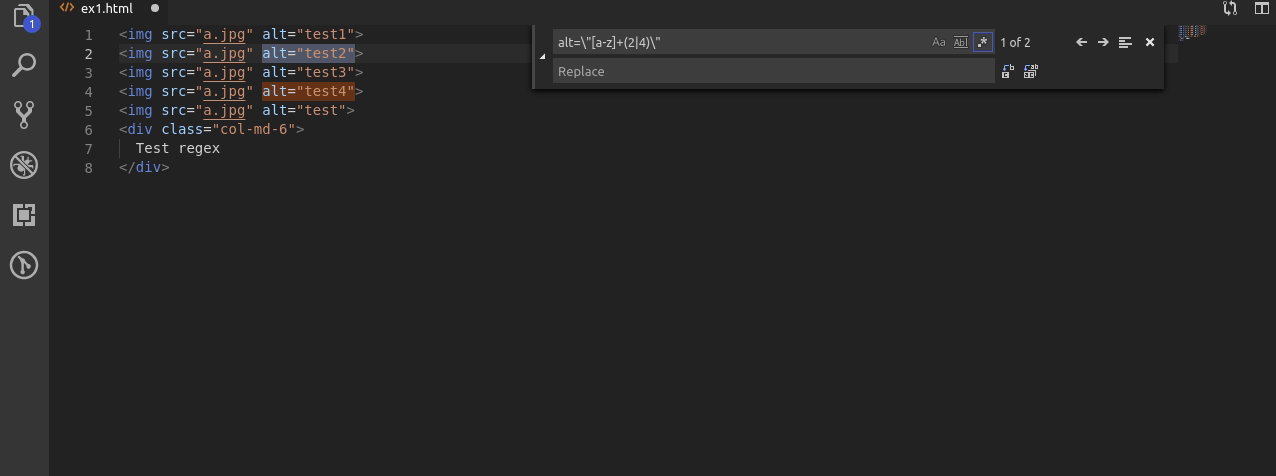
Na początku załóżmy że mamy duży plik html z dużą ilością tagów img które posiadają swoje alty oraz src. Pojawiają się także inne tagi takie jak div.
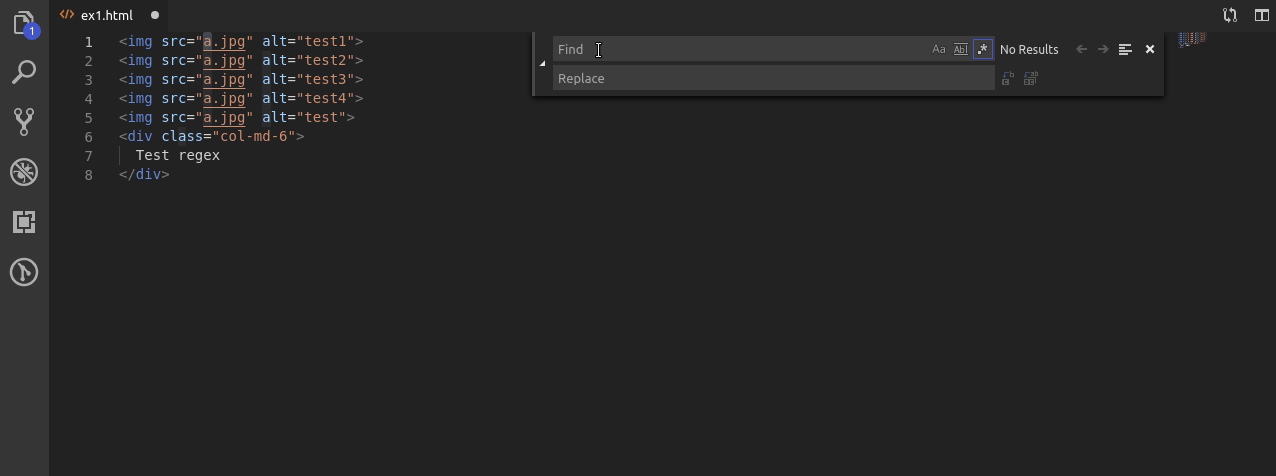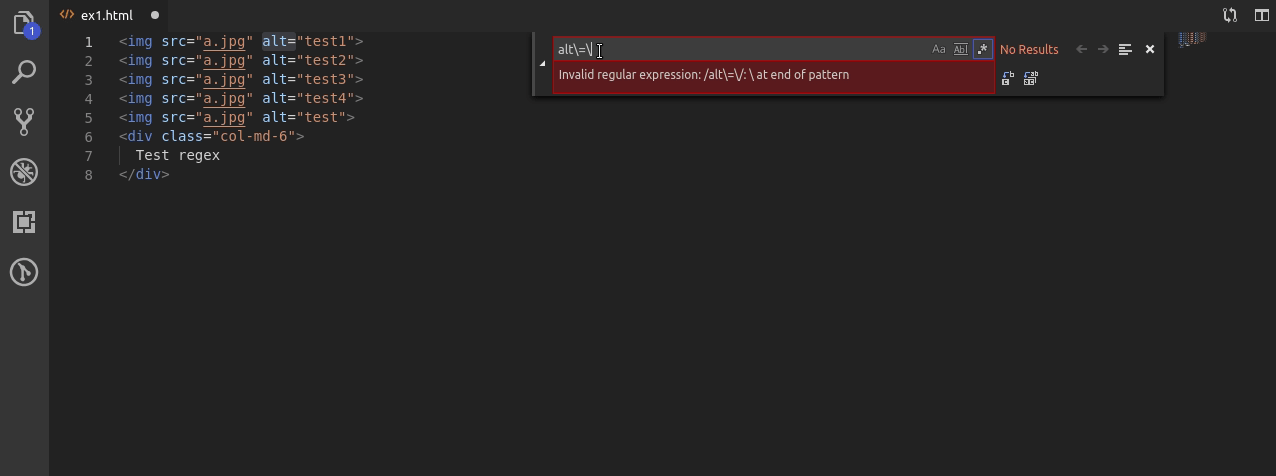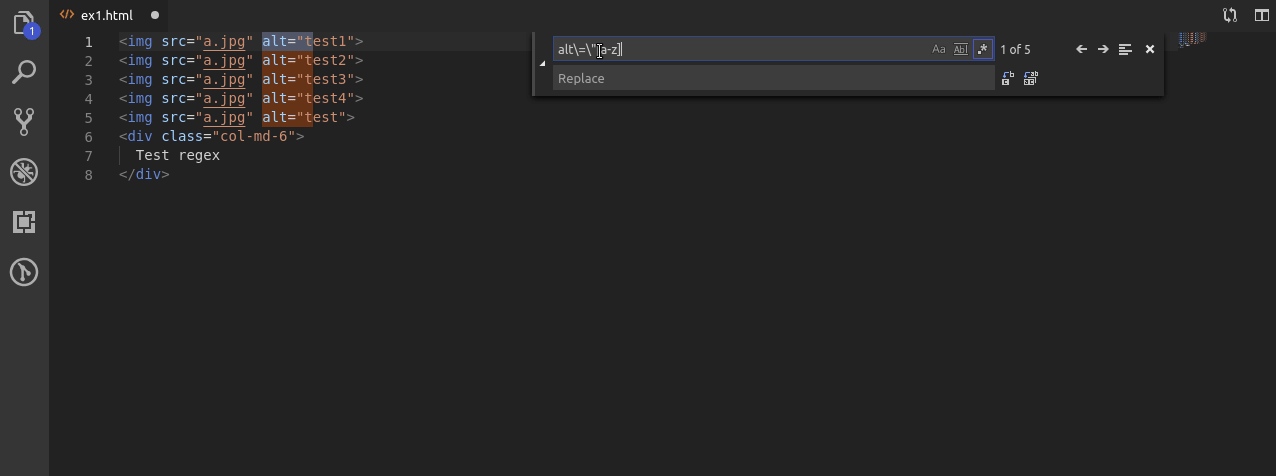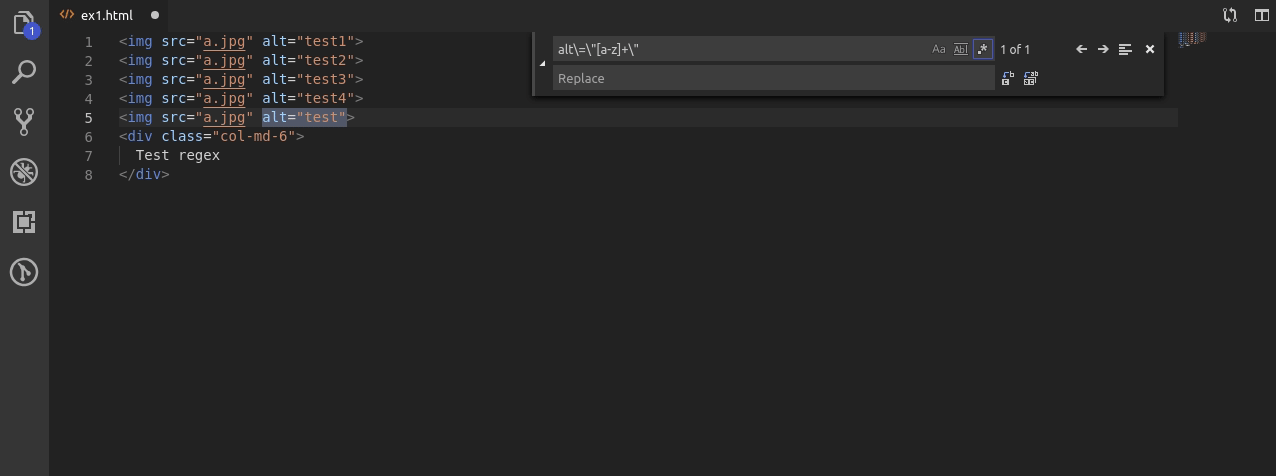
Nasze pierwsze zadanie polegać będzie na znalezieniu obrazka z alt który nie posiada cyfry.
kliknij zdjęcie aby zobaczyć je w większym rozmiarze
Zwróćcie uwagę że w VSC aby używać regexów muszę zaznaczyć trzecią opcję w wyszukiwarce czyli znak .*
Za pomocą wyrażenia: alt\=\”[a-z]+\” wyszukuję tylko takie wyrażenie.
Najpierw szukam alt po którym występuje =, po nim “ a następnie tylko litery z zakresu [a-z] których musi być co najmniej 1 (+). Całość kończę znakiem “.
Teraz kolej na alty ale takie w których występuje co najmniej 1 cyfra.
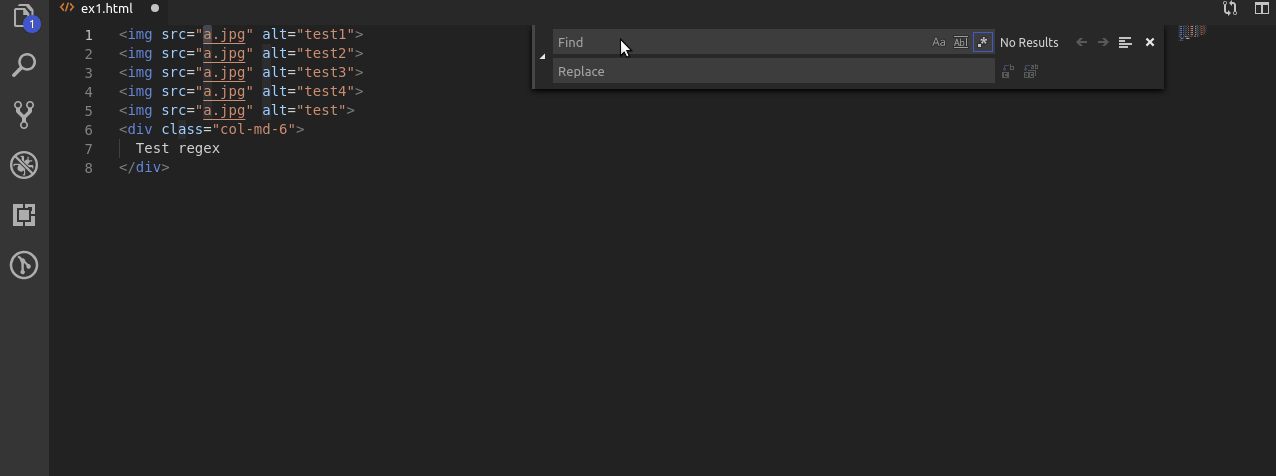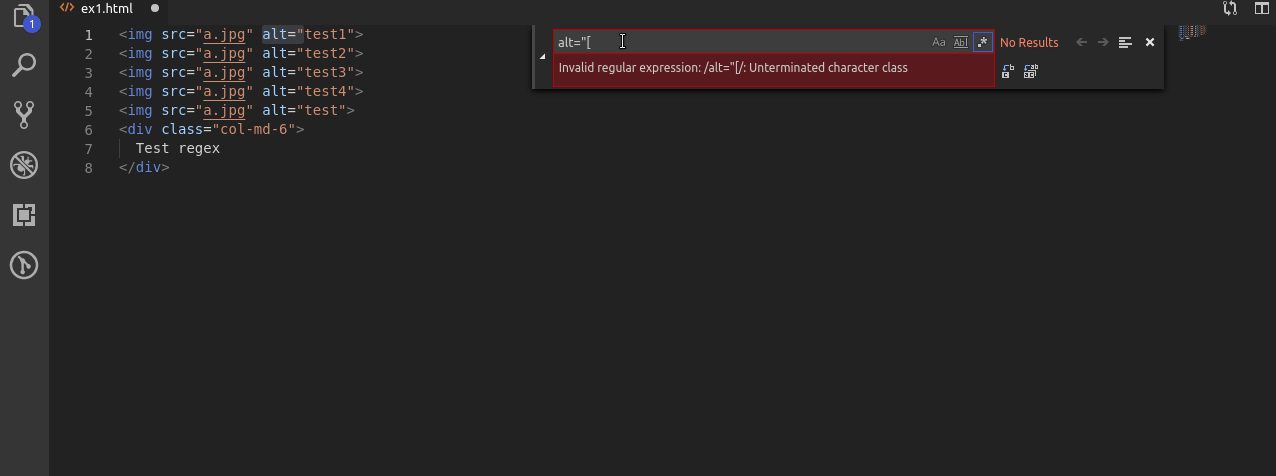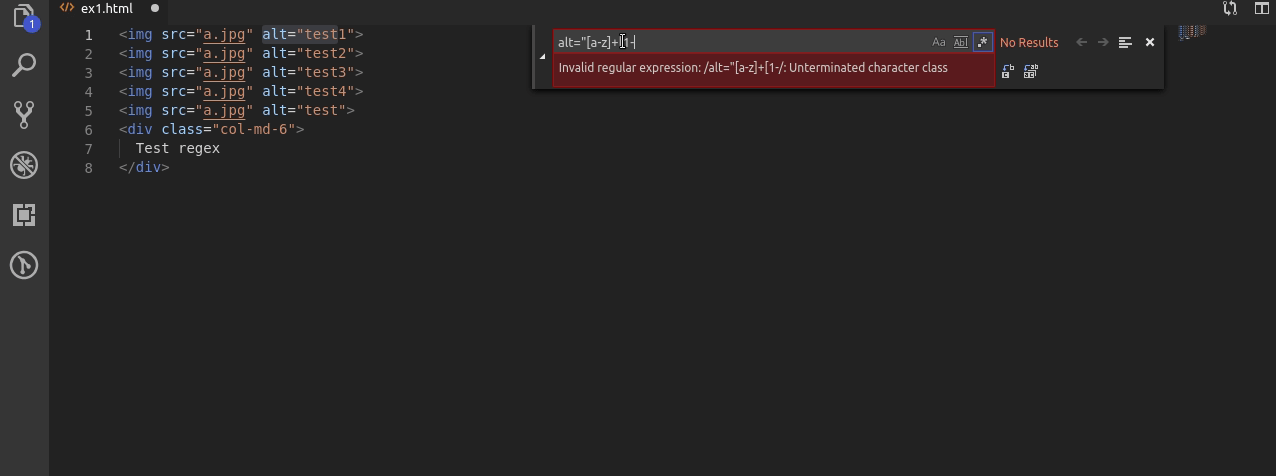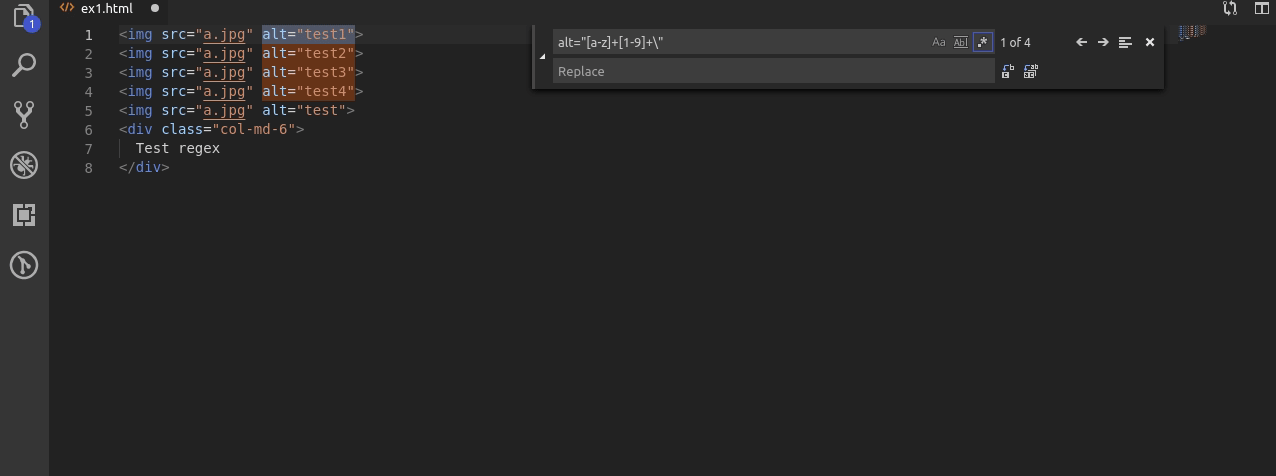
Wyrażenie jest bardzo podobne do pierwszego ale po wyszukaniu liter używam [1-9]+ po to żeby upewnić się że pomiędzy “” występuje chociaż 1 cyfra w tym wypadku z zakresu 1 do 9.
W kolejnym przykładzie zakładam że alt musi mieć w sobie litery oraz co najmniej 1 cyfrę 2 lub 4.
W tym wypadku po wyszukaniu liter tworzę nową grupę za pomocą nawiasów okrągłych, podaje jako 1 możliwość cyfrę 2, używam znaku | który w wyrażeniach regularnych oznacza “lub” oraz wybieram cyfrę 4 jako drugą możliwość.

W tym przykładzie wyszukam wszystkie tagi html które nie są tagami img. Może się to przydać jeśli chcielibyśmy usunąć wszystko oprócz danego tagu lub skopiować cały html bez obrazków.
Najpierw otwieram tag html < następnie używam nawiasów kwadratowych w których jako pierwszy używam znak ^. Neguję on zawartość nawiasu. Oznacza to że szukam wszystkich innych liter oprócz i, m albo g. Następnie wyszukuję wszystkie pozostałe znaki z linii za pomocą wyrażenia .*.
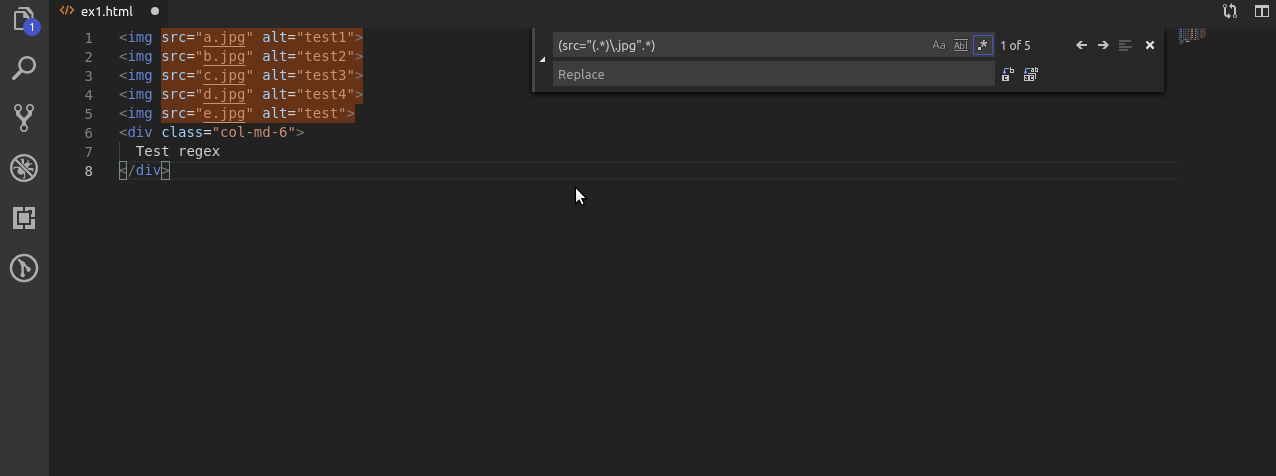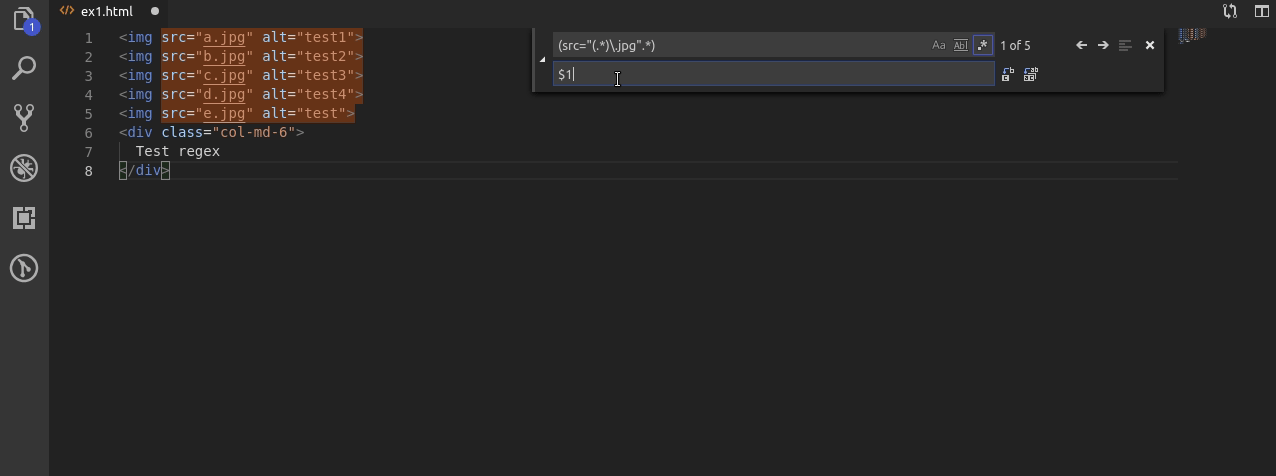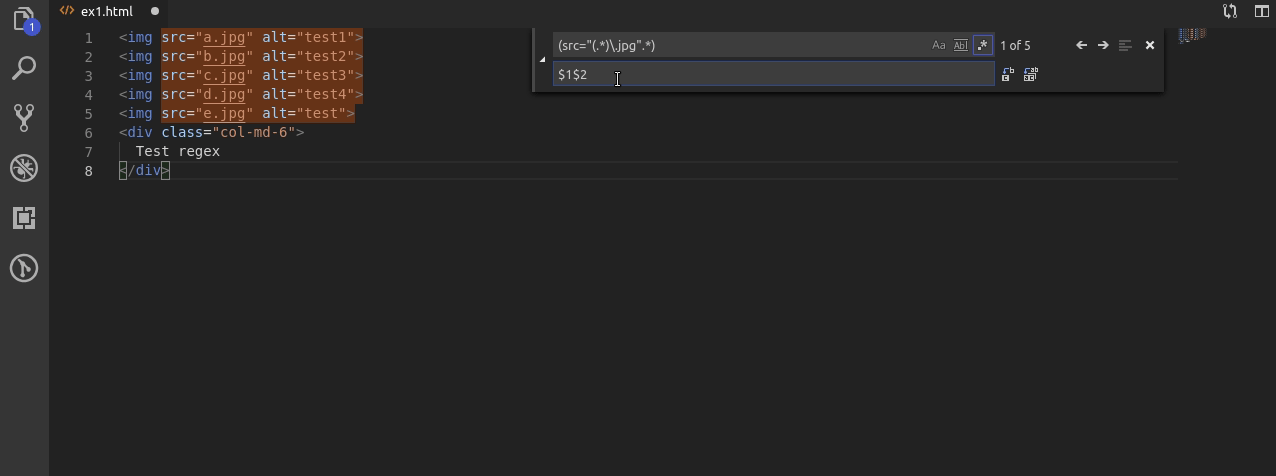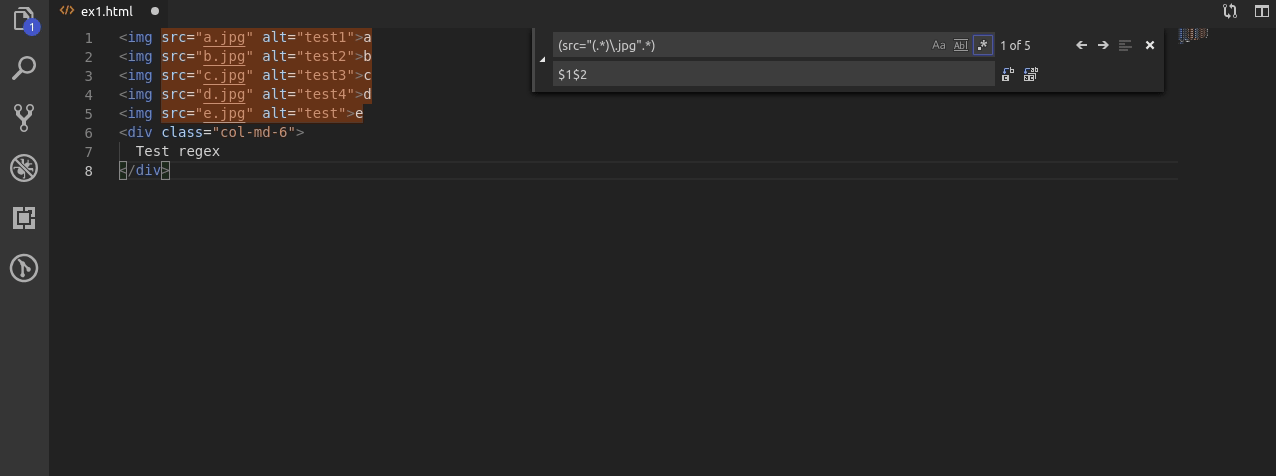
Nawiasy okrągłe w regexach mają jeszcze jedną ważna funkcjonalność. Każdy otwarty nawias tworzy grupę, która jest zapamiętana i do której możemy odwołać się poprzez użycie wyrażenia $ oraz cyfry od 1 do 9. Polska nazwa tego wyrażenia to nawiasy wychwytujące.
W przykładzie korzystam z dwóch takich grup.
Najpierw zapamiętuje całe wyszukiwane wyrażenie, oraz w drugiej kolejności nazwę pliku z źródła src w tagu img.
Dzięki temu po wpisaniu w drugiej linijce narzędzia zamiany wyrażenia $1$2, najpierw z powrotem “zamieniam” znalezione ciągi znaków na te same ciągi znaków a następnie za pomocą $2 dopisuję nazwy plików bez rozszerzenia .jpg.
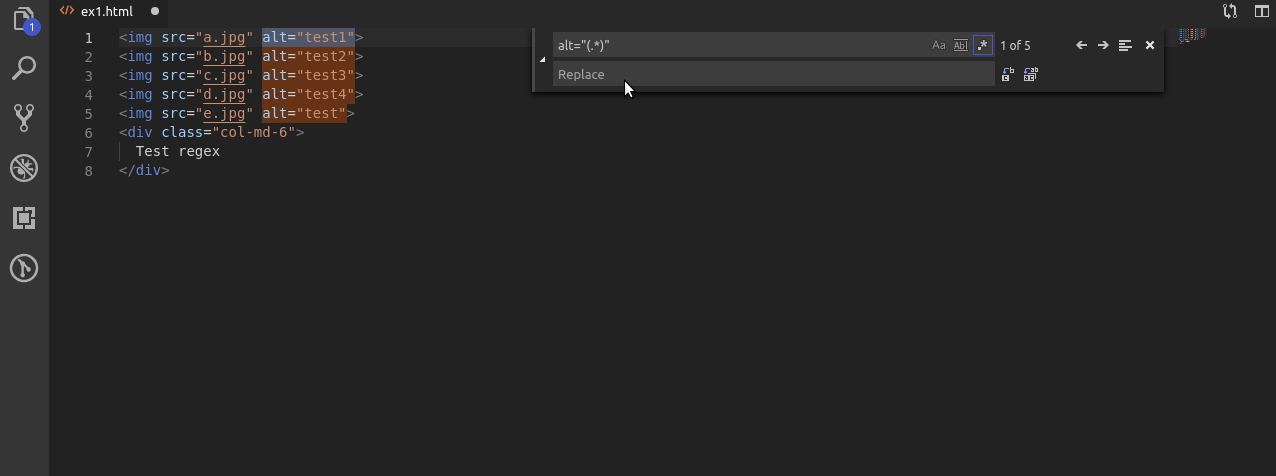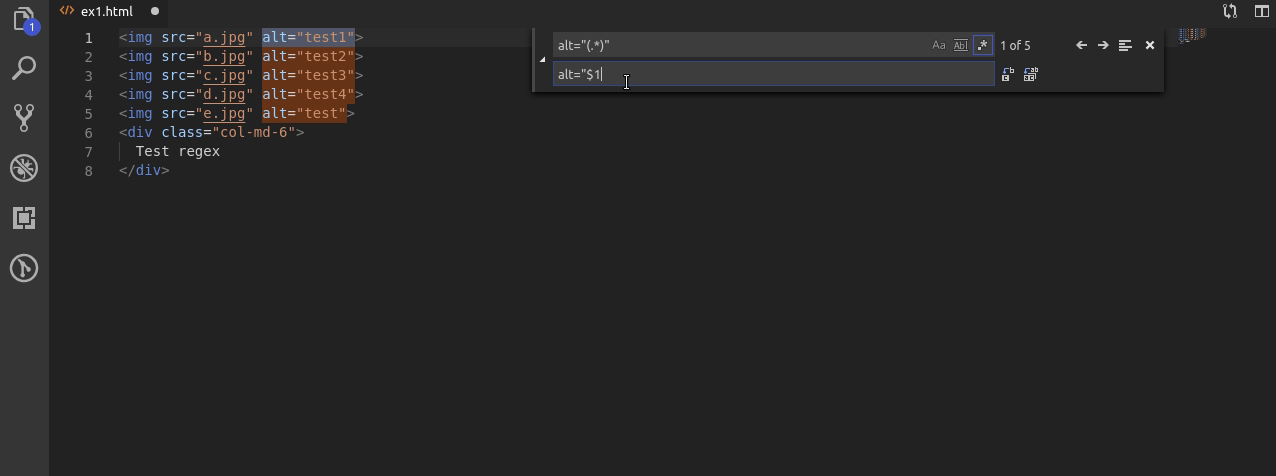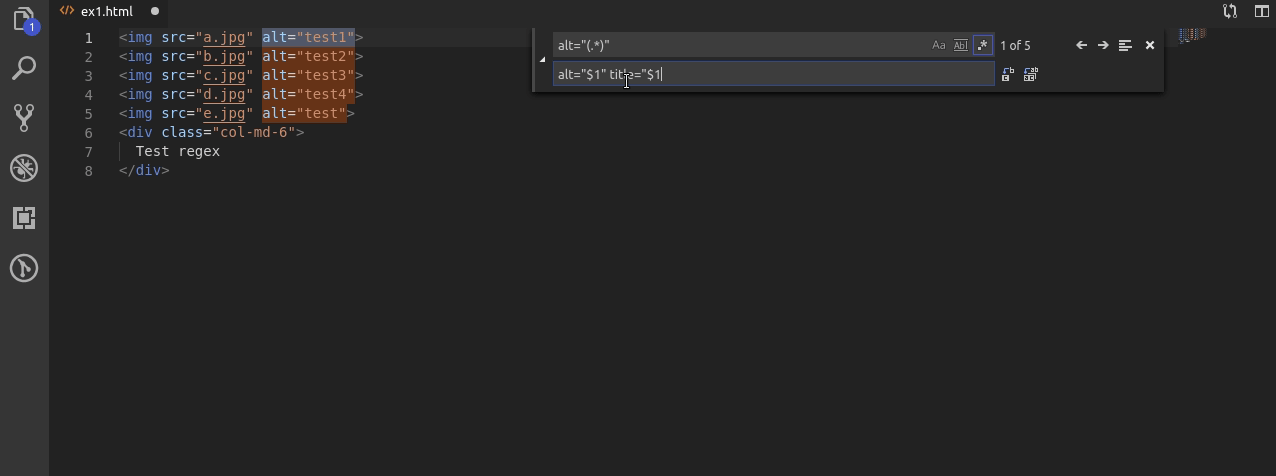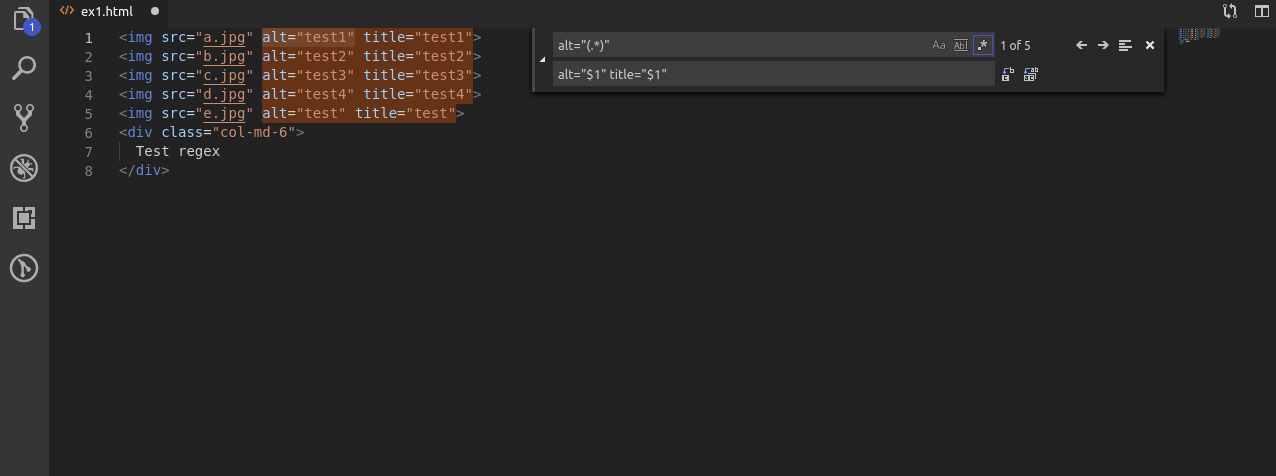
W tym przykładzie dodaje do tagów img atrybut title. Zakładam że ma on mieć taką samą wartość jak alt.
Wobec tego najpierw wyszukuję alt i jego wartość, następnie zapamiętuje wartość oraz w drugiej linijce, najpierw powtarzam alty tak żeby były takie same przy użyciu $1. Później dopisuję title do którego również za pomocą $1 przypisuję ciąg znaków z atrybutu alt.
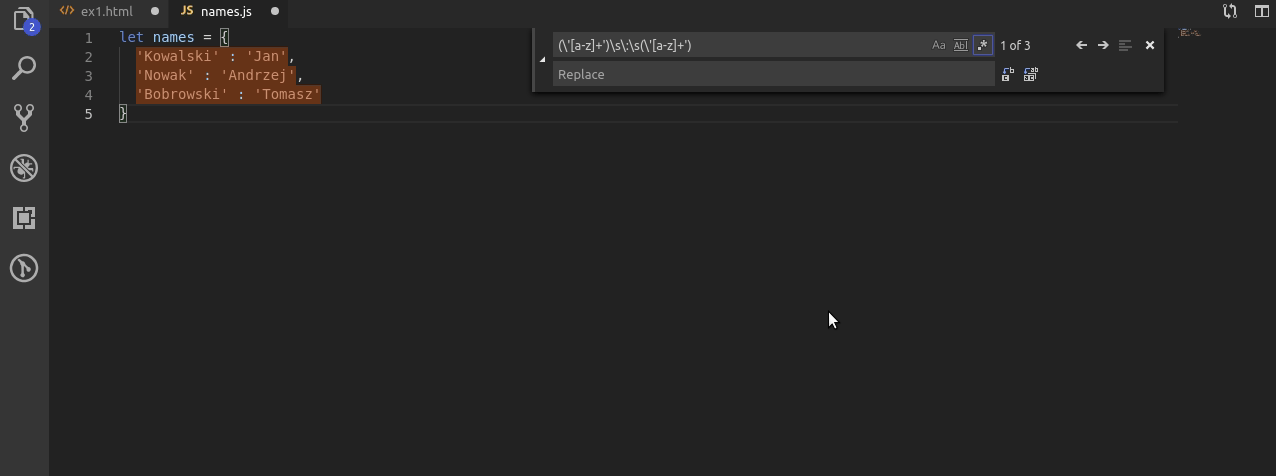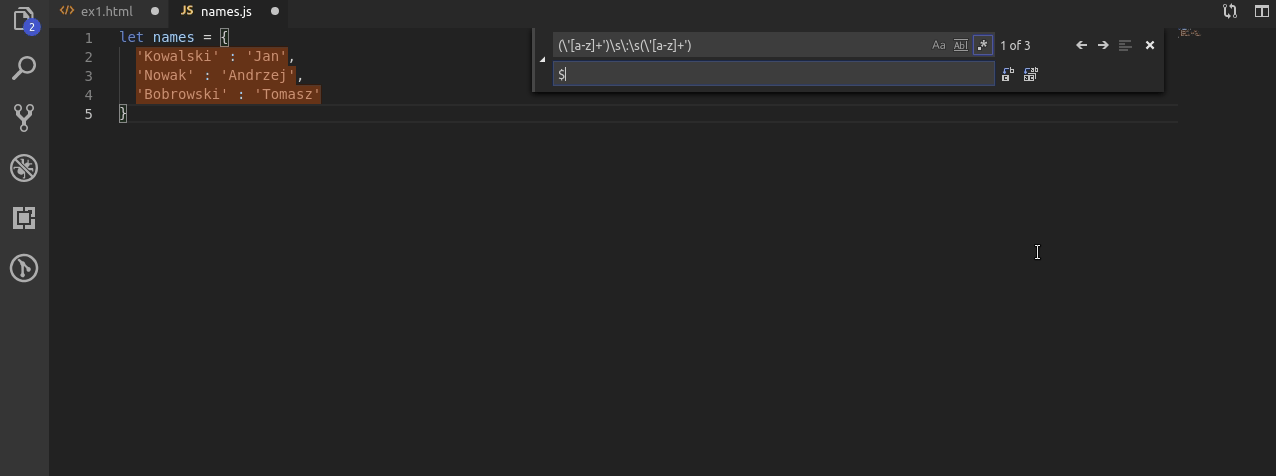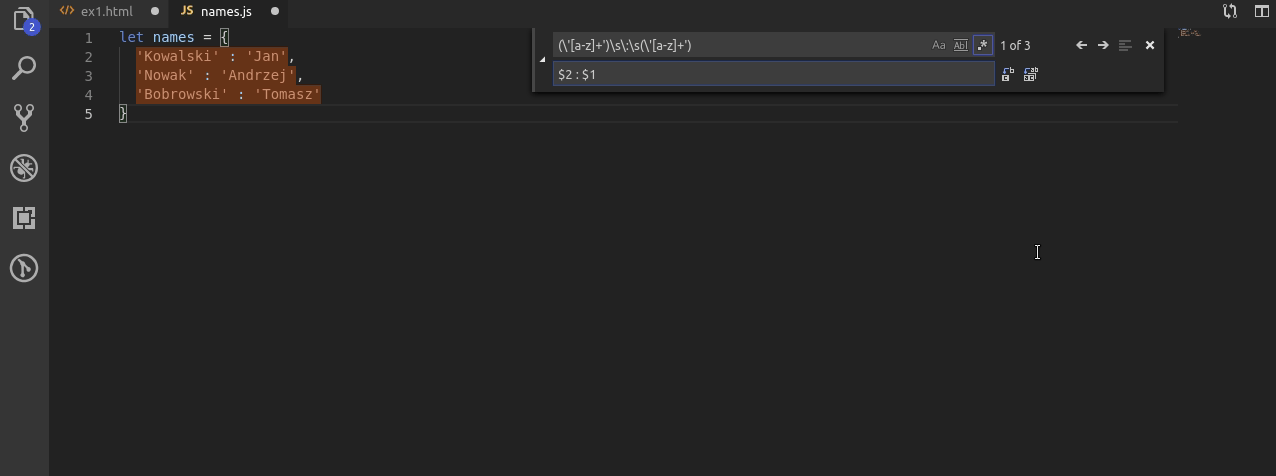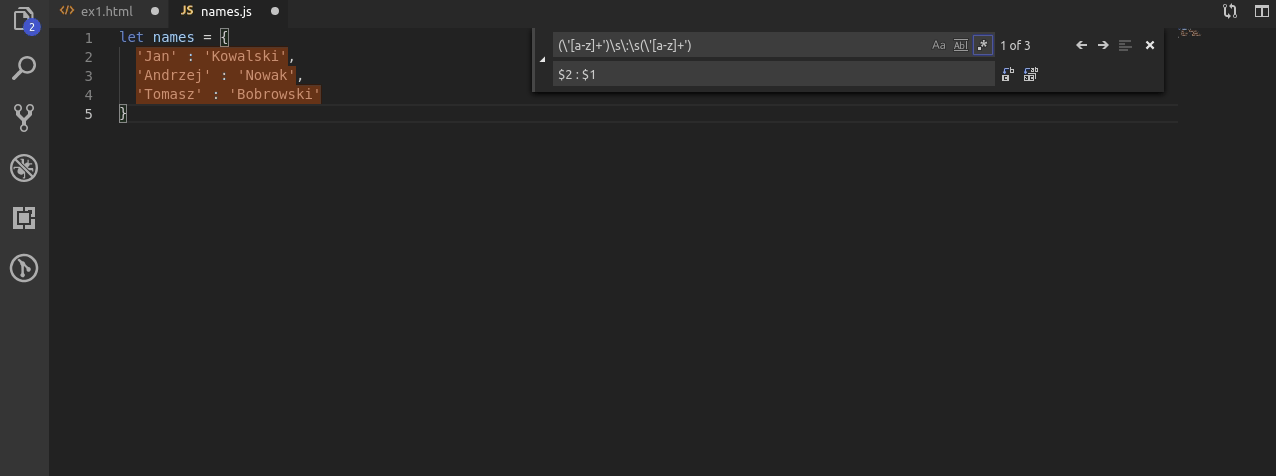
Kiedy nie znałem regexów często podobne zadanie jak to u góry wykonywałem ręcznie. Nie ma jednak się co trudzić!
Dzięki poznanym już grupom najpierw wyszukuję ciąg znaków przed dwukropkiem oraz po. Do jednego przypisuję grupę $1, do drugiego $2. Po czym po prostu odwracam ich kolejność.
Jeśli jesteście ciekawi innych rozwiązań związanych z wyrażeniami regularnymi albo chcielibyście poszerzyć swoją wiedzę na ich temat polecam MDN

 Follow
Follow
















